CS_4641_Project
An Exploration of Machine Learning To Decipher Handwriting
Project maintained by Fried-man-Education Hosted on GitHub Pages — Theme by mattgraham
Final Report
Introduction/Background
This project is an exploration of machine learning as a tool to convert handwriting into ASCII characters for data processing in the real world. Despite the best efforts of Silicon Valley, not everything is digital. We still utilize real world documents as a means of tracking very important information. This information usually needs to be processed in a database or backed up to safeguard the data. Important usecases for this project include, but are certainly not limited to, the healthcare, pharmecuticals, insurance, and banking industries of the world. Millions upon millions of legal documents are created everyday that need to be processed at rates that only pure automation can make feasible. If these documents are failed to be processed in time or are improperly processed, they can lead to a multitude of critical issues for organizations and individuals. This exploration aims to help safeguard and provide an additional tool of measurement for these kinds of documents.
Data Collection
The Dataset used in the project is NIST Special Database 19. The NIST dataset is the most commonly used dataset for handprinted document and character recognition, which includes over 800,000 images of hand-written characters from 3600 writers, with hand-checked classification. The dataset includes digits, upper case English characters, and lower case English Characters.
Due to the limited computational power the team has available, we only used a subset of the NIST dataset, which includes 8,000 images of hand-written characters that includes 0 - 9 digits, A - Z uppercase English Letters, and a - z lower case letters, which comes to a total of 62 classes. The dataset is split into 80% training and 20% testing using Sklearn’s train_test_split method and subsequently split into images and labels. The dataset is also randomly shuffled. Each image has a dimension of 100 * 100 pixels, with 3 RGB channels. Each pixel is then typecasted to float32, and divided by 255 for normalization. The training and testing labels are categorized in the one-hot encoding format using Keras.
Methods
Simple Convolution Neural Networks
In the midterm checkpoint, we applied a simple CNN model on a subset of the data that only contained 0 - 9 digits. We observed an accuracy of 98.84%. The model was faily simple, with two convolution layers, a max pooling layer and a fully connected layer. The model summary is as follows:
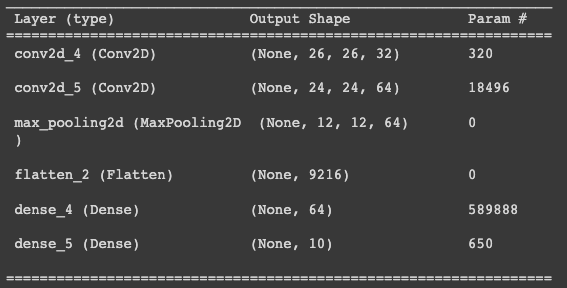
However, when the same model is applied to the dataset with digits, uppercase letters and lowercase letters, the model underperformed significantly. Therefore, we increases the complexity of our CNN model, with 6 convolution layers. Corresponding measures to combat overfitting are also implemented using dropout and batch normalization. A fully connected layer is applied in the end. The model summary is as follows:
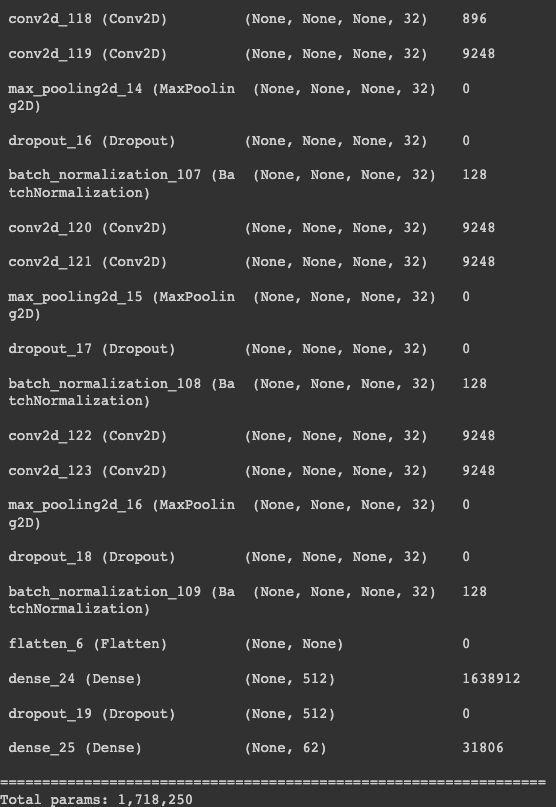
We chose categorical cross-entropy to be the loss function since this is a classification problem. By comparing the label given by CNN to the target label, we assign 1 for every correct classification and 0 for incorrect classification. We chose Adam for our activation function, and the metric we chose is Keras’ accuracy, which computes the frequency in which the predicted label matches the target label. We experimented with different hyperparameters, and found that batch size of 32 and epochs of 20 yield the best result without sacrificing runtime. Higher batch size than 32 lead to generalization and lower accuracy, while lower batch size has a significant impact on memory usage which has a significant impact on our training given the hardware available.
Resnet50, VGG16, DenseNet121, and InceptionV3
Our initial observation from the CNN model above did not show promising results. After reviewing relevant literatures in the area of handwritten recognition, we found several other models that are commonly used. Studies done by Aneja & Aneja and Pramanik & Bag found that Resnet50, VGG16, DenseNet121 and InceptionV3 are top performing model. The models are implemented using Kera’s application library, with each of the model followed by a fully connected layer, and a final classification layer. The models are compiled using the same metrics as the previous CNN model, with the categorical cross-entropy loss, adam optimizer and the same accuracy metrics.
Results
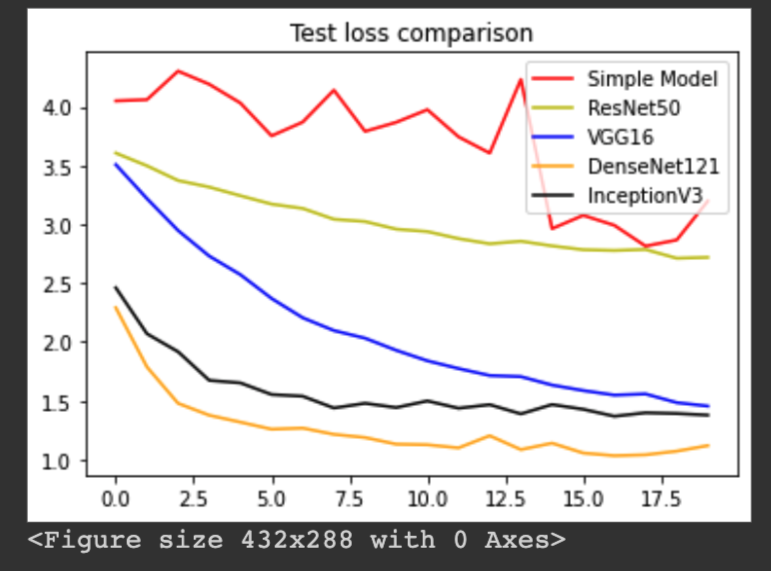
The following plots shows the training accurracy comparison, training loss comparison, testing accuracy comparison, and testing loss comparison:
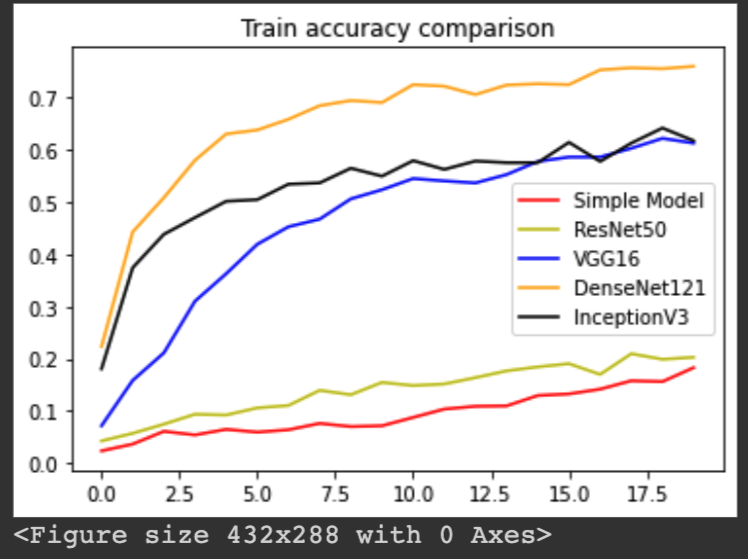
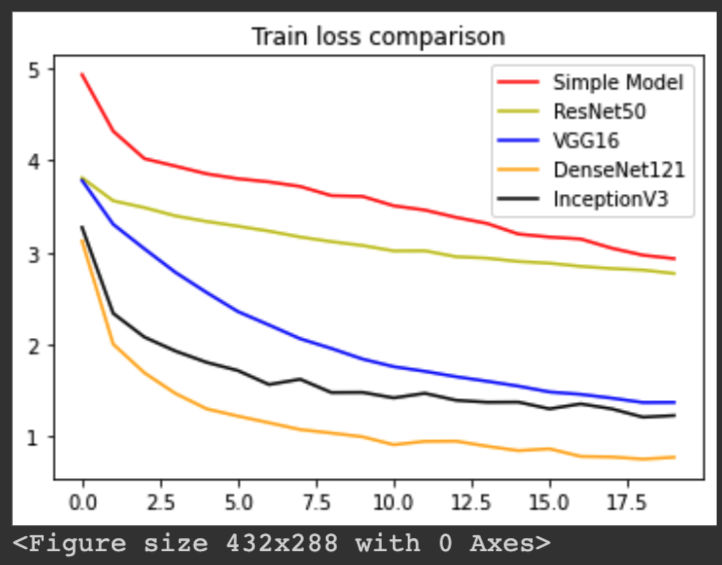
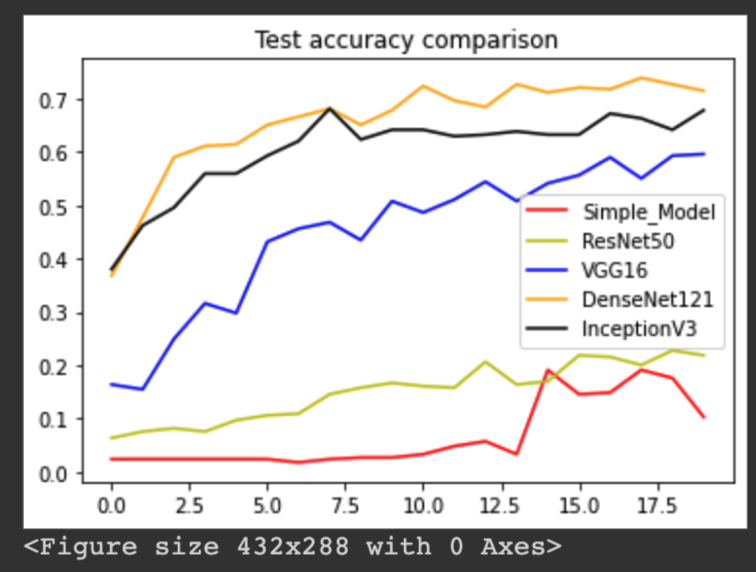
Our results show that DenseNet121 outperformed all the other models, yielding an accuracy of 71.43%. InceptionV3 came second, with an accuracy of 67.78%. VGG16 came third, with an accuracy of 59.57%. ResNet50 came fourth, with an accuracy of 21.88%. And the simple CNN model came last, with an accuracy of 10.33%.
Discussion
Increase complexity and depth in neural networks for complicated classification is widely adopted. While for some cases fewer layer architecutre could sometime achieve similar results, in the case of our project, we found that the 121-layer DenseNet performed the best when classifying 62 classes of handwritten characters and digits. This argument is supported by also the fact that the simple CNN architecutre performed the worst out of all the models.
However, we also see that InceptionV3 model performed similar to that of DenseNet 121. With the use of spatial factorization and efficient grid size reduction, InceptionV3 is able to achieve similar accuracy while having a significanly less complicated model compare to DenseNet 121. Arguments can be made for a tradeoff between accuracy and computational complexity.
Our simple CNN model suffered from underfitting when applied to dataset with 62 classes, as we can see from the training accuracy plot. While it performed well when classifying only 10 digits, with a more complicated 62-class classification, the model is simply not able to capture the relationship between the input pixels and target labels.
Conclusion
While our models weren’t perfect in accuracy, they provided a series of realworld solutions to an important problem. There is a lot of room for tweaking on our models to squeeze out better results. This exploration provided the group with a route of model experience to test ourselves in. Overall, the project is a succesful step forward.
References
Aneja, N., & Aneja, S. (2019). Transfer learning using CNN for handwritten devanagari character recognition. 2019 1st International Conference on Advances in Information Technology (ICAIT). https://doi.org/10.1109/icait47043.2019.8987286
He, T., Huang, W., Qiao, Y., & Yao, J. (2016). Text-attentional convolutional neural network for scene text detection. IEEE Transactions on Image Processing, 25(6), 2529–2541. https://doi.org/10.1109/tip.2016.2547588
Pramanik, R., & Bag, S. (2021). Handwritten Bangla City name word recognition using CNN-based transfer learning and FCN. Neural Computing and Applications, 33(15), 9329–9341. https://doi.org/10.1007/s00521-021-05693-5
Yousef, M., Hussain, K. F., & Mohammed, U. S. (2020). Accurate, data-efficient, unconstrained text recognition with convolutional neural networks. Pattern Recognition, 108, 107482. https://doi.org/10.1016/j.patcog.2020.107482